
A journey through the world of AI
Following our exploration of AI’s capabilities in evaluation and decision-making, we now take a fundamental journey into the core concepts that make these advanced applications possible. This presentation delves into the beginnings of artificial intelligence, examining how computers “intelligently” think and make decisions.
This deep dive into neural networks, backpropagation, and the historical evolution of AI provides a crucial foundation for understanding both current capabilities and future possibilities in AI development.
Key topics covered
The presentation guides attendees through a comprehensive exploration of artificial intelligence, focusing on:
Historical context
The history of artificial intelligence (AI) traces back centuries, starting with Greek mythology, which imagined automated beings like Talos, the metal guardian. In the 20th century, with the advent of computers, AI became a tangible concept as pioneers like Alan Turing laid the groundwork for algorithms and machine learning. Early programs for chess and problem-solving in the 1950s and 1960s marked the beginning of research in this field. Today, AI is integrated into our daily lives through virtual assistants, autonomous vehicles, and recommendation algorithms, shaping the future of technology.
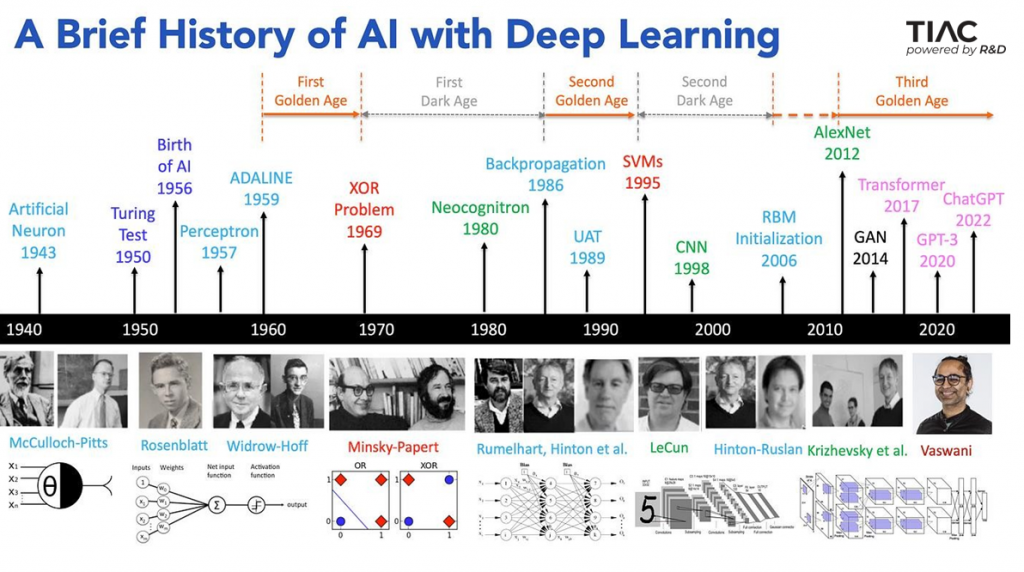
Neural network fundamentals
Neural networks are computational models inspired by the biology of human neurons. Each artificial neuron receives inputs, processes them through an activation function, and produces an output. These networks are organized into layers: the input layer receives data, one or more hidden layers process the information, and the output layer provides results.
During the learning process, neural networks use algorithms like backpropagation to adjust the weights between neurons based on errors in predictions. These weights are crucial, determining the influence each neuron has on the output. Neural networks excel at pattern recognition, making them suitable for tasks such as image recognition, speech processing, and prediction. Deep neural networks, which feature multiple hidden layers, enable more complex processing and drive advancements in machine learning and AI.
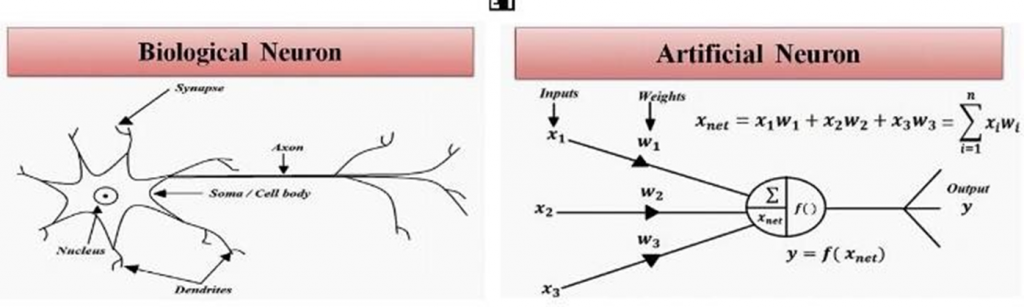
Overall, neural networks have become essential tools in modern technology, driving innovations across various industries.
Backpropagation algorithm
Backpropagation is a critical algorithm for training neural networks, based on gradient descent. When a neural network processes inputs and generates outputs, the error between its predictions and the actual targets is calculated. This error is then used to adjust the network’s weights.
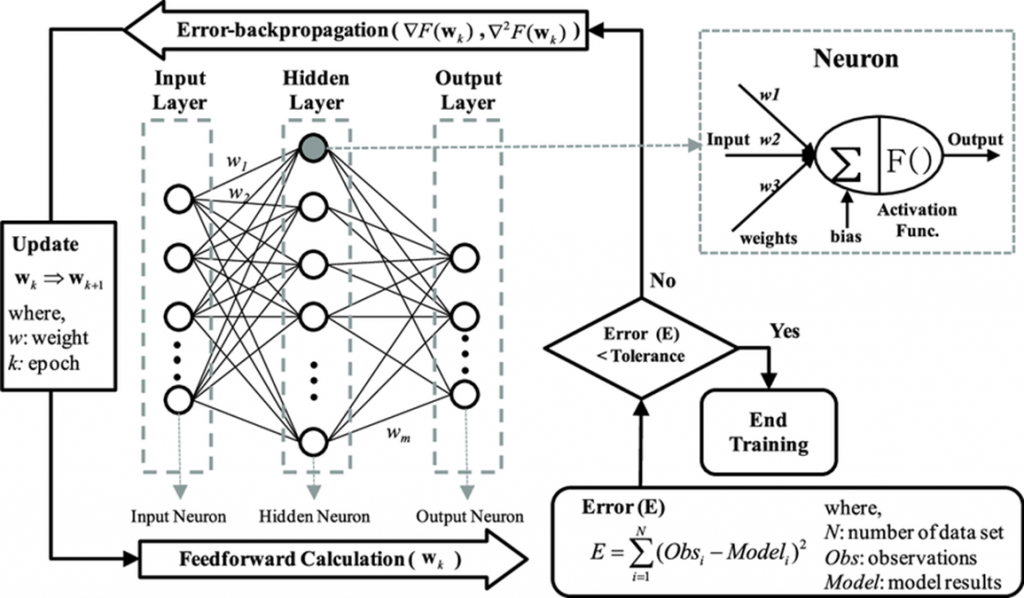
The backpropagation process involves several steps:
- Forward pass: The input data passes through the network, layer by layer, generating predictions.
- Error calculation: The error is calculated using a loss function, which measures the difference between the prediction and the actual output.
- Backward pass: The error is propagated backward through the network. Using the chain rule of calculus, partial derivatives of the loss function with respect to each neuron’s weights are computed, determining how weight changes affect the overall error.
- Weight update: Based on these derivatives, the weights are updated using the gradient descent algorithm, reducing error. A learning rate controls the speed of weight adjustments.
Backpropagation’s efficiency has made it the standard in machine learning, enabling advanced AI system development and making the training of deep neural networks feasible within reasonable timeframes.
Technologies and real-world applications
- TensorFlow: Developed by Google, this framework supports complex neural networks and various platforms.
- PyTorch: A dynamic programming framework by Facebook, PyTorch is favored for its simplicity and flexibility, especially among researchers.
- Keras: A high-level API for fast neural network development, often used on top of TensorFlow.
- MXNet: Known for its support of distributed learning and efficiency with large datasets, MXNet supports multiple programming languages, including Python and Scala.
- Caffe: Popular for convolutional networks, especially in computer vision applications.
- Scikit-learn: A versatile Python library offering simple implementations of fundamental machine learning models, including basic neural networks.
- Fastai: Built on top of PyTorch, Fastai simplifies model setup and training, emphasizing practical learning.
From simple neurons to sophisticated neural networks, the evolution of AI highlights both the impressive progress made and the exciting possibilities and challenges that lie ahead.
As we’ve explored how computers simulate intelligent decision-making through neural networks and backpropagation, this foundation is essential for understanding both the capabilities and limitations of AI.
In the next part of the blog, we’ll discuss how LLMs process information, solve tasks, and support developers in creating advanced solutions, as well as their limitations and areas for improvement.
A journey through the world of LLM
In the exploration of AI technologies, large language models (LLMs) like GPT and BERT take center stage. By examining the transformative nature of the Transformer architecture and its contributions to deep learning advancements, they provide a comprehensive view of the architecture and innovations that enable LLMs to recognize and generate natural language with high accuracy and adaptability. Let’s dive together into the mechanisms and implications of these revolutionary models.
Deep learning
Deep learning is a field within machine learning that uses artificial neural networks, inspired by the structure and function of the human brain, to analyze large amounts of data and learn patterns from them. This enables systems to recognize complex patterns and make decisions without explicit programming for each task.
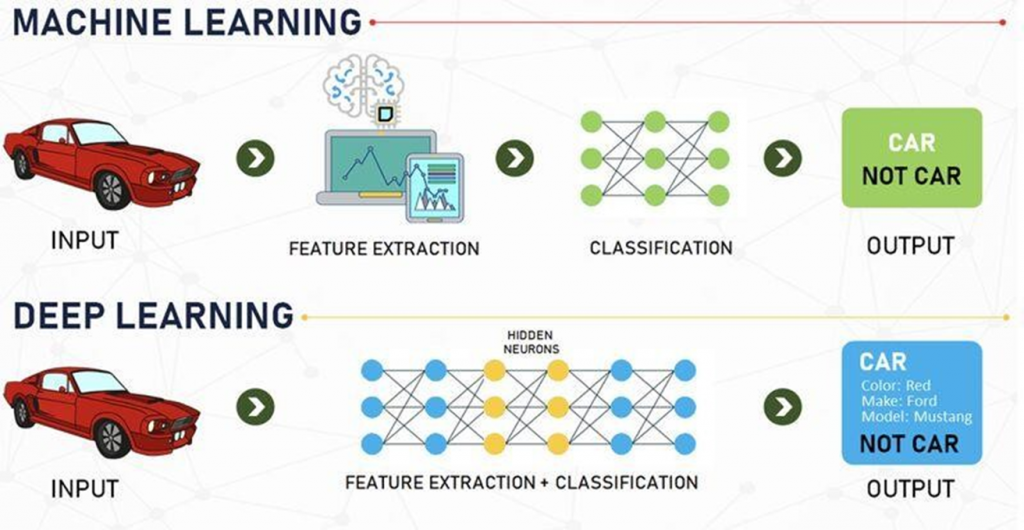
It’s particularly useful in tasks like speech recognition, image processing, and natural language understanding, where deep networks (layered structures of neurons) are trained on massive datasets, achieving high accuracy.
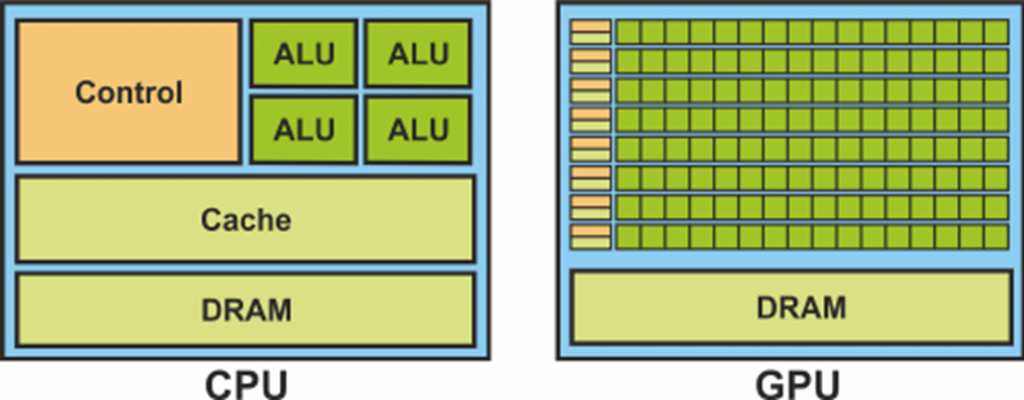
CPU and GPU
The CPU (Central Processing Unit) and GPU (Graphics Processing Unit) are processors designed for different types of data processing. The CPU is a general-purpose processor that performs complex operations, focusing on serial tasks, meaning it executes instructions one by one, which makes it suitable for most computationally intensive tasks.
On the other hand, the GPU is specialized for parallel processing and can handle thousands of tasks simultaneously. This structure makes it ideal for graphics operations and working with large datasets, such as rendering images or training machine learning models. While the CPU has a smaller number of powerful cores, the GPU has a large number of less powerful cores optimized for tasks that require high parallelization.
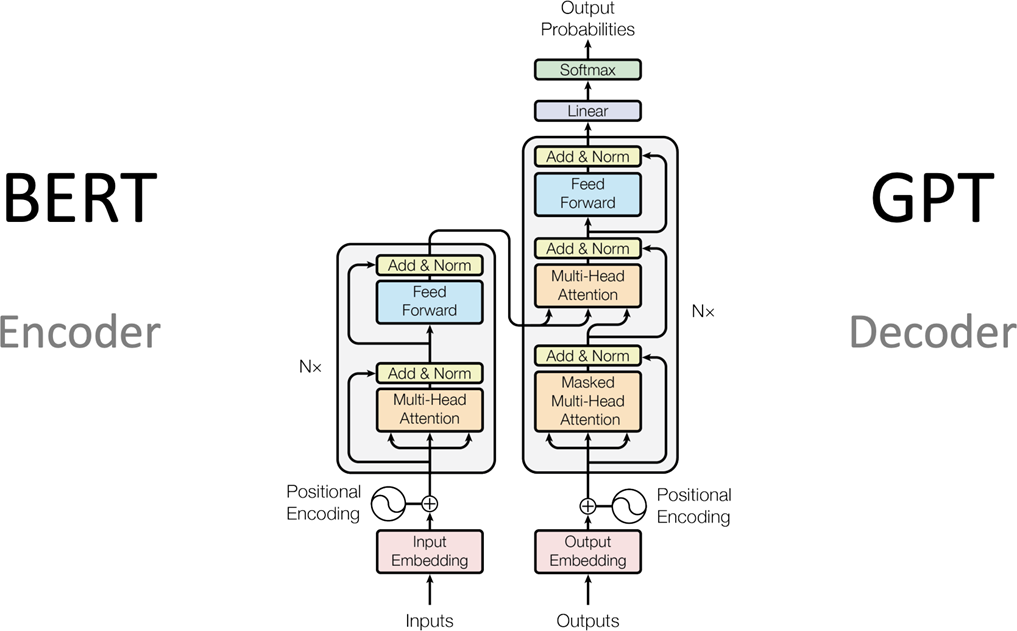
The transformer architecture
The Transformer architecture is a deep learning model that has revolutionized natural language processing and many other fields. Introduced in the research paper “Attention is All You Need” (2017), it is based on the attention mechanism, which allows the model to dynamically “attend” to different parts of the input sequence regardless of its length.
Transformers use complex layers of attention instead of recurrent and convolutional layers, enabling simultaneous processing of all words in a sentence (parallel processing). The key components are self-attention layers, which allow the model to recognize relationships between words at different positions in the text, and positional encoding, which adds information about the order of words in the sequence.
Transformer models, such as BERT and GPT, have led to significant advancements in tasks like language translation, text generation, and summarization, as they can scale to very large datasets and deep networks.
GPT2
GPT-2 (Generative Pre-trained Transformer 2) is a deep learning model developed by OpenAI for generating high-quality text based on given input. This model utilizes the Transformer architecture, which has revolutionized the field of natural language processing (NLP) and many other domains. Transformers rely on the attention mechanism, allowing the model to dynamically “attend” to different parts of the input sequence, thereby overcoming the need for recurrent or convolutional layers.
The core components of the Transformer architecture include:
- Attention layers: These include self-attention mechanisms that enable the model to recognize relationships between words in a sentence regardless of their position. This allows for a better understanding of context and the essence of the text.
- Positional encoding: Since Transformers do not process input data sequentially, positional encoding adds information about the order of words, allowing the model to understand the structure of a sentence and the relationships between words.
- Feed-Forward layers: These layers are used for further processing of data after attention, enabling the model to learn more complex patterns.
- Layer normalization: This is used to stabilize and accelerate the training process, improving the overall efficiency of the model.
- Residual connections: These help preserve information during the learning process and enable the model to learn complex functions without losing significant information.
In addition to these components, GPT-2 uses key parameters to control text generation, including temperature, top-k, and top-p:
- Temperature: This parameter determines the “creativity” of the model in generating text. A lower temperature (e.g., 0.2) results in more predictable, consistent responses, while a higher temperature (e.g., 0.8) allows for more creative and diverse generation, but may lead to less coherent text.
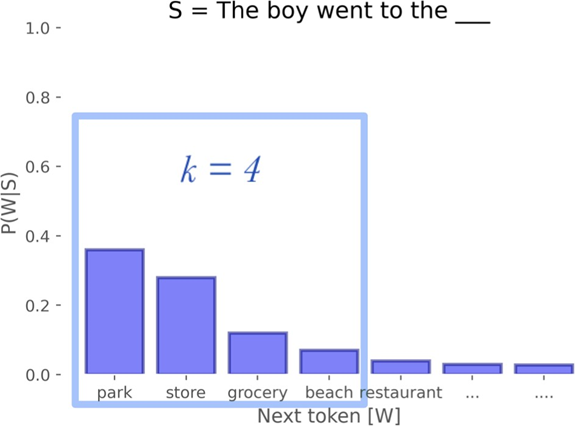
- Top-k: This limits the number of words the model considers at each generation step by selecting only the k words with the highest probability. For example, a top-k of 10 means the model chooses only among the 10 most probable words, thus avoiding the selection of less relevant words.
- Top-p (nucleus sampling): This sets a cumulative probability threshold, selecting words until their total probability reaches a specified level (e.g., 0.9). This approach allows for dynamic word selection, contributing to a balance between stability and creativity.
By combining these parameters, users can tailor the text generation process, from conservative and focused outputs to more creative and free-form styles. GPT-2 represents a significant advancement in the development of language processing models, enabling a wide range of applications in natural text generation, and its features and flexibility allow for easy adaptation to specific user needs.
Conclusion
The Transformer architecture has laid the groundwork for the development of large language models (LLMs) and has become a key component in modern natural language processing applications. Its ability to efficiently handle long sequences of data through the attention mechanism has enabled models such as GPT, BERT, and many others to achieve outstanding results in tasks like language translation, text generation, and summarization.
However, despite its advantages, the Transformer architecture and LLMs have several significant drawbacks:
- Computational requirements: Training and using large models requires substantial computational resources, including powerful GPUs and large amounts of memory, which can be expensive and impractical for smaller organizations.
- Training data: These models rely on massive amounts of training data, which can lead to issues such as biases in the data and the potential for generating inaccurate or inappropriate information. If the data is biased, the models will also exhibit biases in their responses.
- Lack of understanding: Although Transformer models can generate text that sounds natural, they do not understand context in the way that humans do. Their “understanding” is based on patterns in the data, which can lead to superficial or inadequate responses in more complex situations.
- Lack of generalization: In some cases, these models may struggle to generalize knowledge to new or unknown concepts, which can limit their application in specific domains or tasks.
- Ethics and responsibility: The use of LLMs can raise ethical and responsibility issues, especially when it comes to generating misinformation, propaganda, or offensive content. It is essential to establish rules and guidelines for the use of these technologies to minimize potential negative consequences.
While the Transformer architecture is incredibly powerful and revolutionary in the field of machine learning, it is crucial to be aware of its limitations and challenges. Further development of these models requires careful consideration of ethical, practical, and technical aspects to ensure their responsible use.